I’ve made many music videos. This is my most recent one. I released it on YouTube on July 20, 2026. I think it’s one of the best I’ve made because it’s more than just singing; it’s more like a story with cinematic shots throughout.
For reference, here’s the original music video, which was released on August 24, 2000.
Personally, I like my version of the music video more, not because I made it, but because the original video has seemingly irrelevant and random scenes, and I don’t care for some of the dance moves. Also, the actual singing only covers a portion of the vocal sections of the song, and the singing clips are often wide shots, so it’s unclear whether they’re actually singing or not.
Anyway, here’s how I made the music video.
1. Get a Song
Sometimes, I create music using AI in Suno. For this music video, I chose an existing Bollywood song called “Kya Maine Aaj Suno” from the movie “Harama Dil Aapke Paas Hai”. It’s an old song from August 24, 2000.
Note: I’m not Indian, and I don’t speak or understand Hindi. It’s just a song I had in my music library from a long time ago that I thought might make a good music video. I used Google Translate to translate the lyrics from Hindi to English, but the translation didn’t make much sense, so I used ChatGPT to make sense of it.
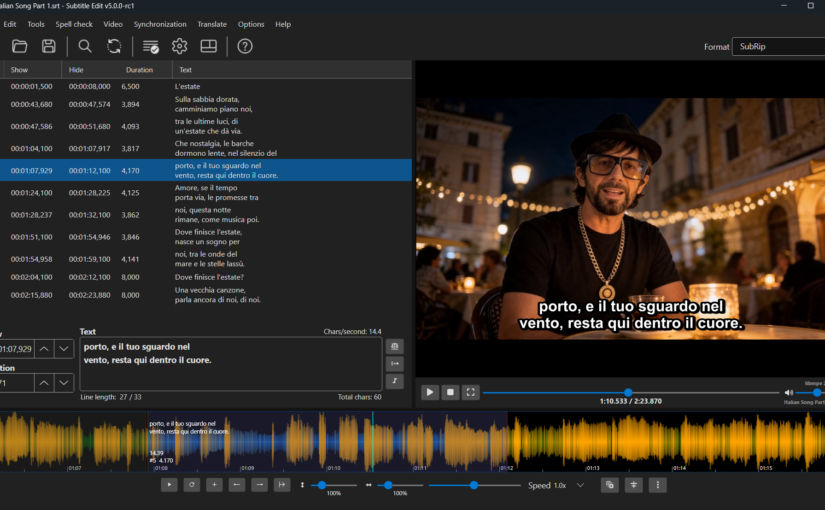
2. Create Subtitles
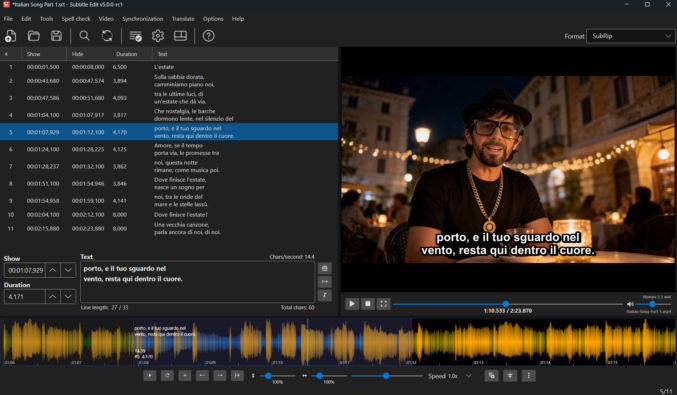
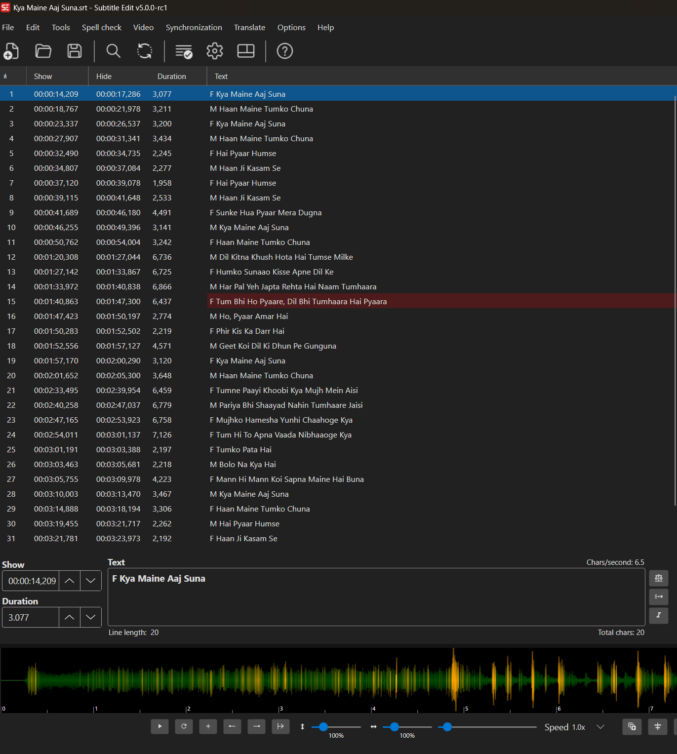
I used SubtitleEdit (free) to create the subtitles. SubtitleEdit can’t import mp3s, so I converted the song (mp3) to a video with a black screen in mp4 format and imported the video. I then manually created the subtitles since auto-subtitle generation is often wrong, especially for non-English audio. I made sure each lyric line time range started exactly or slightly before the vocals for that lyric.
3. Create Character Sheets
When I made music videos, I like to star in them, but I like to change my appearance, except my face, to match the theme of the song. So, for a Chinese song, I have AI create a character sheet of me but with typical Chinese clothing and a hairstyle suitable to the theme of the song. Here’s an actual image of me taken with my phone.

I then used ChatGPT to create a character sheet of me with a gold necklace. This is what it generated. You can start to see my facial identity drift a little, but it’s still close enough and acceptable.

I then told ChatGPT to replace my hat with hair of a male Bollywood singer and to add a full-body shot. This is what it created. You’ll notice that my facial details drifted even further, but I figured it was still close enough and acceptable, so I settled with this character sheet for the male singer (me).

For the female singer, I started with this photo.

I asked ChatGPT to remove the red dot on her forehead, remove her necklace and the gold thing on her head, and give her white, fitted pants. Here’s what ChatGPT generated. Since I wasn’t trying to recreate a real person, whatever looked good was acceptable, so I chose this character sheet.

4. Create Black-Screen Video Clips for Each Lyric
I used CapCut for video editing and SeeDance 2.0 to generate the final video clips for each lyric. SeeDance generates videos at 24 frames per second (fps), so I set CapCut to create 24 fps videos.
To have SeeDance generate an accurate lip-sync video, I need to give it a reference video with the singing audio. You can upload a reference audio to SeeDance, but for some reason it doesn’t work as well as a reference video. So, I just created a bunch of black-screen video clips, one for each video clip. SeeDance 2.0 supports video generation between 4 and 15s. I make sure each black-screen video clip starts when the vocals start for a particular lyric and ends on an integer number, e.g., 8s instead of 8s and 13 frames. Here’s what I did to create the black-screen video clips.
- Import the full song (mp3) to the timeline
- Extract the vocals using https://uvronline.app/ai (this is necessary for better lipsync by removing any background and instrumental sounds)
- Add the vocals audio (mp3) to the timeline
- Import the subtitles (srt file) into CapCut and add to the timeline
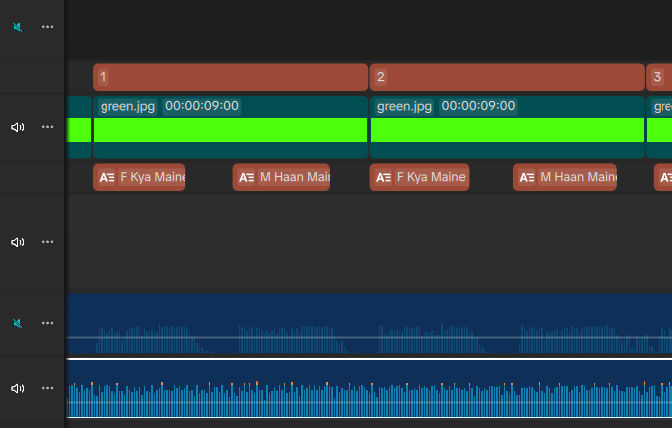
In order to see the duration of a clip, I found it easier to import a solid green image to CapCut, add it to the timeline. The left edge should line up with the start of the subtitle element. The right edge should end either at the end of the subtitle element or after it, and it should be a whole number in seconds, not seconds plus frames. I also like to add text to the timeline with just a number so I can see which video clip I’m working on. In the screenshot below, you’ll see the tracks from top to bottom are
- text elements labeled 1, 2, and 3 to see which track I’m working on
- solid green elements to easily see the start and end of a clip and the duration
- the start and end of each lyric from the subtitles file
- the vocals-only audio
- the full-song audio
For clip 1, I decided to group lyrics 1 and 2 into one video clip. This particular song has alternating male/female vocals, e.g.,
- lyric 1 is a female voice, which I prefixed with “F”, e.g., F Kya Maine Aaj Suna.
- lyric 2 is a male voice, which I prefixed with “M”, e.g., M Haan Maine Tumko Chuna
Notice how the green element for this clip is exactly a whole number (9s long).
After repeating this process for each section that will be converted into a video clip, I
- hid all visible elements (text and solid green),
- disabled the full-audio track
- enabled the vocals-only track
and exported each clip in 480p (the picture quality doesn’t matter since these videos clips are for audio reference only) and named each clip by its ID, e.g., audio1.mp4, audio2.mp4, etc.
For comparison, here’s clip 1, full audio and vocals only.
Note: sometimes, I would make a black-screen video longer than its lyric duration so its duration would be a whole number in seconds. I would then simply trim the end so that the clip ends when the next vocal segment begins.
5. Plan the Video Storyboard
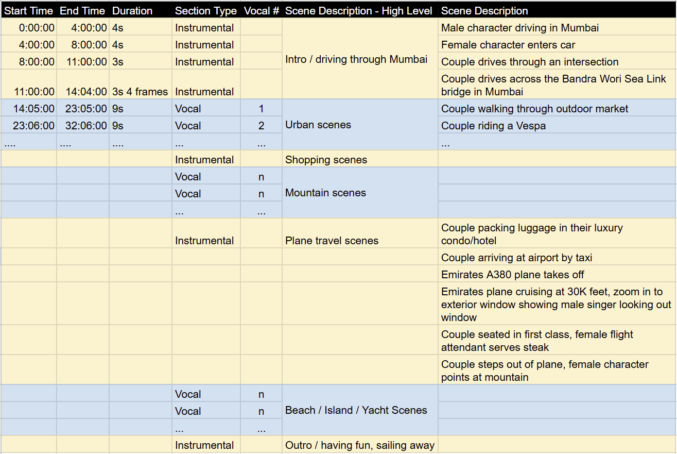
Once I had all clips grouped in CapCut and all vocal segments exported as black-screen video clips, I created a storyboard in Excel like this. The yellow sections are instrumental sections. The blue sections are vocal sections. Since I wanted this music video to be more like a mini movie with a story as opposed to a bunch of random clips, I used this storyboard to help plan the story. I used ChatGPT to propose scenes for each clip.
6. Create Lipsync Video Clips
Since lipsync video generation is difficult, I started with these clips and left the instrumental sections for last. I used SeeDance 2.0 via Kie.ai. At first, I tried SeeDance 2.0 mini, but the lipsync quality was bad and inconsistent. There’s SeeDance 2.0 Fast, but I decided to stick with the regular version of SeeDance 2.0. Since this version is expensive, I generated lip-sync clips at 480p and generated non-lip-sync (instrumental) clips at 1080p, since the higher the resolution, the higher the cost.
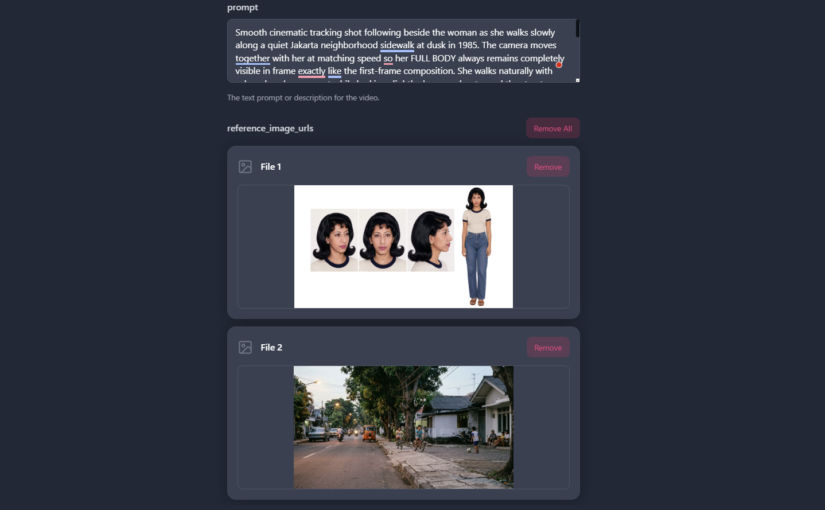
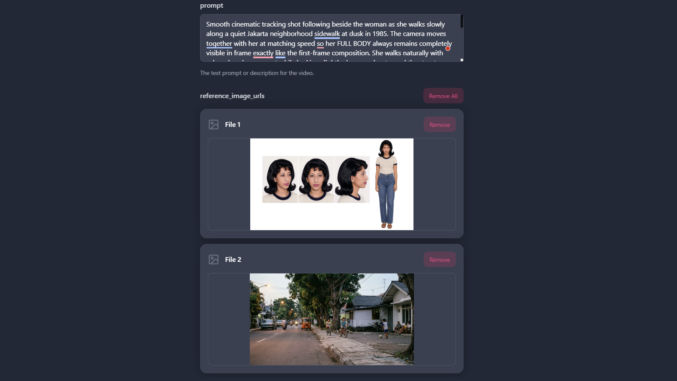
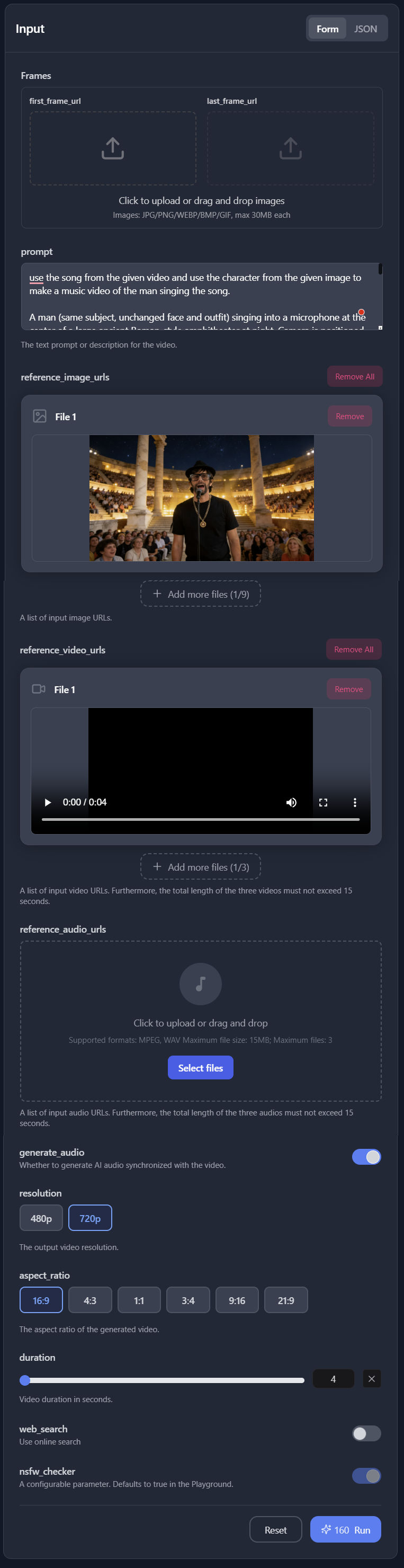
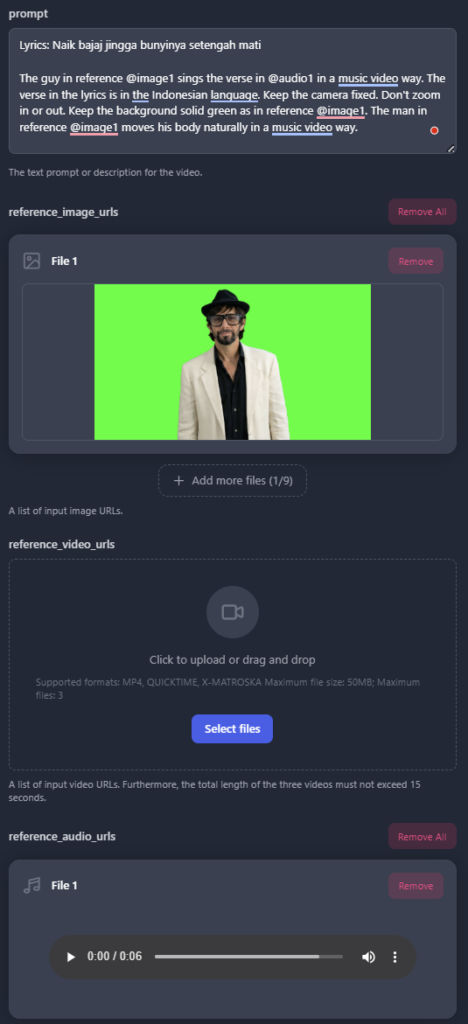
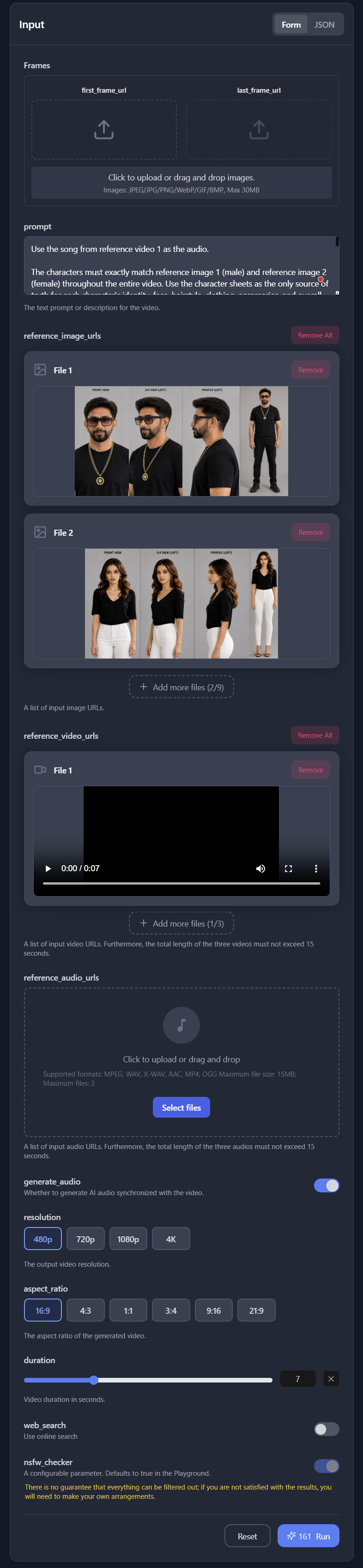
Whenever a clip included both characters, I added their character sheets as reference images. For the audio to be lip-synced to, I added the black-screen video clip. The duration is set to match the duration of the black-screen video. For the actual prompt, I asked ChatGPT to generate it for me. The prompts can become very long but very detailed, resulting in highly professional and cinematic results. For example, here’s one prompt for just one lip-sync clip.
Use the song from reference video 1 as the audio.
The characters must exactly match reference image 1 (male) and reference image 2 (female) throughout the entire video. Use the character sheets as the only source of truth for each character's identity, face, hairstyle, clothing, accessories, and overall appearance.
Exactly two people appear in the entire video: one male matching reference image 1 and one female matching reference image 2. No other people appear at any time.
Identity continuity is critical. From the very first frame to the final frame, the left character must always remain the male from reference image 1, and the right character must always remain the female from reference image 2. The female must already appear as the correct female in the very first frame, before she begins singing. Never duplicate the male. Never duplicate the female. Never swap, morph, replace, transform, or blend the two characters at any point. Changing singers must affect only lip-sync and facial performance. It must never change either character's identity, face, body, clothing, accessories, gender, or position in the frame.
Lyrics:
Tumko Pata Hai\nBolo Na Kya Hai
This is a romantic Bollywood duet.
The scene takes place on a beautiful tropical island wooden pier extending into crystal-clear turquoise water on a bright sunny afternoon. The luxurious white motor yacht from the previous scene is docked behind them along the pier, naturally continuing the story. Palm trees sway gently on the nearby white-sand beach while small tropical islands are visible in the distance beneath a brilliant blue sky.
The couple stands comfortably side-by-side on the wooden pier, facing slightly toward each other while enjoying the peaceful ocean surroundings.
There is absolutely no physical contact between them at any point. No hand holding, no touching, no hugging, no kissing, no leaning against each other, and no body contact of any kind. Maintain a small, natural gap between their bodies throughout the entire scene. Their romance is expressed entirely through warm smiles, affectionate eye contact, natural facial expressions, and relaxed body language.
The video is one continuous cinematic shot with no cuts.
The camera begins with a medium waist-up shot from slightly in front of the couple and slowly performs a smooth sideways dolly along the length of the pier while maintaining approximately the same distance from them. The movement should feel elegant, stable, and cinematic. Throughout the shot, the turquoise ocean remains visible on both sides of the pier while the yacht, palm trees, and tropical island scenery create beautiful depth in the background.
The female sings the lyric:
"Tumko Pata Hai."
She lip-syncs perfectly to the original audio while smiling playfully at the male, as though teasing him with a secret. Her expression conveys warmth, affection, and gentle curiosity.
As she finishes, the male immediately replies:
"Bolo Na Kya Hai."
He lip-syncs perfectly to the original audio while smiling warmly back at her. His expression conveys playful curiosity, happiness, and affectionate encouragement, inviting her to continue. He may briefly raise his eyebrows with a natural friendly expression before smiling again.
Only the currently singing character lip-syncs the lyrics. The other character maintains a gentle, natural smile with subtle facial movements, breathing, blinking, and realistic expressions, but never mouths the lyrics or appears to sing. Changing the active singer must never change either character's identity or appearance.
Both characters blink naturally, smile subtly, and make small natural head movements. Their body language should feel relaxed, elegant, affectionate, and comfortable together while always maintaining the small gap between them. Avoid exaggerated acting or large gestures.
A gentle tropical breeze softly moves their hair and clothing. Bright sunlight creates sparkling reflections across the turquoise water and soft natural highlights on their faces, giving the scene a luxurious, peaceful, and romantic atmosphere.
No scene changes. No cuts. No dancing. No text. No subtitles.
Modern Bollywood movie style. Bright tropical daylight. Crystal-clear turquoise water. Rich saturated colors. Highly realistic. Beautiful cinematic composition. Natural facial expressions. Accurate lip-sync that follows the original reference audio exactly.Here are all the video prompts used in the video.
As an example, here’s one generated lip-sync clip. Notice the audio is the vocals-only version. Later, this audio from this clip will be muted and replaced with the full audio.
7. Create Additional Reference Images
When a series of video clips contains the same object and object consistency is important, I create a reference image for that object. For example, in the instrumental intro of the music video, I show a Rolls-Royce convertible across multiple clips. To ensure SeeDance creates a consistent-looking car, I created this reference image.

In addition to the two character reference images, I added this car image as a third reference.
8. Review, Export and Upscale Final Video
Once all clips have been generated and added to the timeline, I previewed the entire compilation and when it looked good, I exported it at 720p since my instrumental clips were generated at 720p. The 480p lip-sync clips would just get upscaled to 720p, but not using AI. I then reviewed the 720p-version of the full video and when it looked good, I upscaled it to 4K using Topaz Video AI. If you want the best quality video, you can have SeeDance generate video clips in 4K, but it will be much more expensive than 480p and 720p.
9. Generate YouTube Thumbnail
To generate the YouTube thumbnail image, I used SeeDream 5.0 on Kie.ai. ChatGPT gave me the prompt and I uploaded the two character sheets. Here’s the generated thumbnail that I approved.