



In this post, I’ll show how I made this AI video containing a consistent main character.
Note: as I made this video, I kept finding and learning better ways to make it, so this video is not as good as could be had I started over using the techniques in this post.
Decide on a theme/setting
I wanted to make a music video using the song “When You Believe” from the movie “The Prince of Egypt”. For that reason, I chose ancient Egypt for my setting.
Create your main character
I wanted to see if I could create an AI version of me with changes to suit my desired main character, i.e., I wanted the character’s face to look as close as possible to me, but have other features like physique be more athletic and sculpted. To create the main character, I chose a picture of me that I liked and I asked ChatGPT to give me a prompt to create an image of a person that matches an example image I found.

ChatGPT analyzed the outfit in the image I uploaded and gave me a prompt to generate an image with that outfit applied to a reference image I would upload. For the reference image, I chose this picture of me.

In OpenArt, I did the following
- Image > Create Image
- Model = Nano Banana
- Uploaded my reference image to the Omni Reference input
- Clicked “Create”
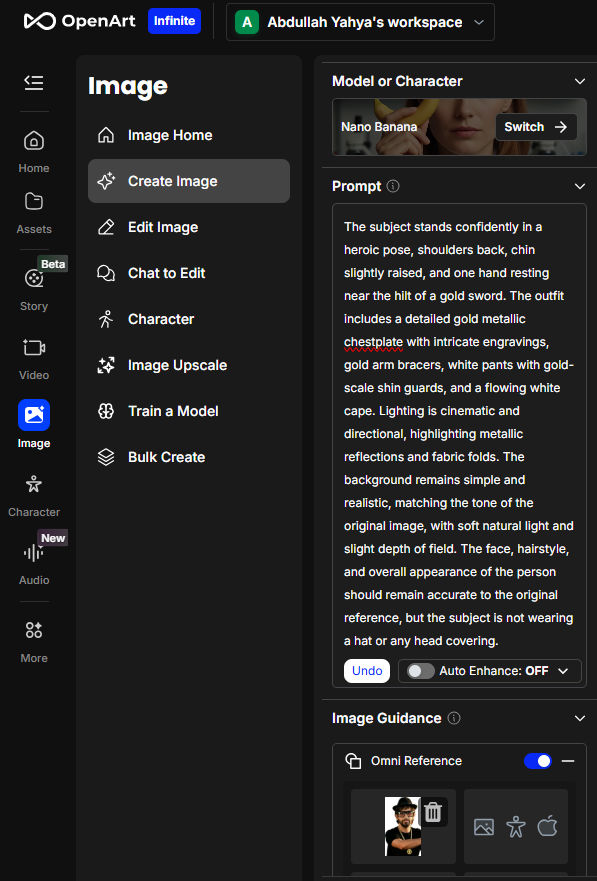
Nano Banana gave me this:

It was good, but I ended up making various changes until I got this:

This final character image is based on another photo of mine. Tweaking the character photo was a lot more difficult than it should have been. I had to tell Nano Banana to make my arms a little darker and have me facing straight at the camera. When you create your main character, whether from a photo of a real person or not, try to have the character standing straight and facing the camera with a neutral facial expression. In my image above, I have a little smile, which kept getting carried over into various AI image generations. To fix this, I had to update every prompt that used this image to include the comment, “Subject is not smiling”. Also, AI generations would often remove my sunglasses, even though my main character reference image includes sunglasses. To fix this, I had to update every prompt that used this image to include the comment, “Subject is wearing glasses or his sunglasses.”
Note: Make sure you are satisfied with your main character image because you will use it to generate many images and videos with it as a reference.
Decide on your video content structure
In my case, I didn’t want to show viewers the main character non-stop throughout the video, so I decided to have alternating clips showing clips with and without the main character, i.e.
| Scene 1 | Video clip without the main character |
| Scene 2 | Video clip with the main character |
| Scene 3 | Video clip without the main character |
| Scene 4 | Video clip with the main character |
| Scene 5 | Video clip without the main character |
| Scene 6 | Video clip with the main character |
| … | … |
Generate image and video prompts
Generating images is much cheaper than generating videos. For example, in OpenArt, here’s what I paid in credits for each type:
| Image using Flux Pro model | 5 credits |
| Image using Nano Banana model | 16 credits |
| Video using Kling 2.5 model | 100 credits |
For this reason, I created an image of the first frame of each scene (video clip) before creating each video clip. If I didn’t like an image that was generated, I could regenerate it, which is much cheaper than regenerating a video.
For the scenes without the main character, I didn’t need a reference image, so I used the Flux Pro model, which was cheap (5 credits) and produced great results.
For the scenes containing the main character, I needed to upload my reference image. Flux Pro doesn’t support reference images, so I used the Nano Banana model, which does support reference images.
UPDATE: actually, SeeDream 4.0 is just as good as Nano Banana. Use both SeeDream and Nano Banana, then choose which result you prefer.
For video generation, I chose Kling 2.5 because it supports a first-frame image option and produced good results.
Since we want the final video not to show a bunch of random content, I had each pair of consecutive scenes with and without the main character be relevant to each other. To do this, and to generate detailed prompts that matched my theme and setting, I used ChatGPT. For example, I asked ChatGPT the following:
Give me 10 pairs of cinematic video prompts along with their first-frame image prompt. For each pair, the first set of image and video prompts will not include my main character reference image, and the second set of image prompts will include my main character reference image.
I will use Flux Pro to generate images that don’t include the main character, I will use Nano Banana to generate images with the main character reference image, and I will use Kling 2.5 to generate each video using the corresponding image as the first frame. Every detail that will be referenced in the video prompt should be included in the image prompt.
Since I am making a music video of the song “When You Believe – The Prince of Egypt”, the theme/setting of the scenes should be ancient Egypt. The scenes should include popular landmarks, like the pyramids and the Nile River, people in a busy market, ancient mosques, and, of course, a royal palace for the prince. Each pair of prompts with and without the main character should be relevant to each other so as to flow as a story. If possible, all scenes should flow together as a cohesive story.
After answering a few follow-up questions from ChatGPT, it gave me the prompts, like the following:
1. The Desert Procession (without the prince)
Image Prompt (Nano Banana)
Epic realism, ancient Egyptian soldiers and servants walking through golden desert dunes at dusk, carrying ornate banners and treasures toward a distant palace on the horizon. The sky glows crimson-orange, sand whipping lightly in wind, dust haze around the caravan, footprints trailing through rippled dunes. Cinematic depth, ultra-detailed, 50mm lens realism, warm atmospheric glow.
Video Prompt (Kling)
Dynamic tracking shot alongside the caravan; camera glides parallel to marching servants, banners flapping, sand swirling, sunlight catching on gold ornaments; as the procession nears the palace, a subtle lens flare crosses frame, suggesting the arrival of royalty; ambient desert wind and drum rhythm underscore the movement.
2. The Prince’s Arrival (with the prince)
Image Prompt (Nano Banana)
Epic realism, regal Egyptian prince wearing a black tunic with gold trim, ornate jewelry, and a linen cloak, descending from his chariot before the grand palace gates. Behind him, the same caravan from previous scene arrives in the background. The palace gleams under the last light of sunset, palm trees swaying gently, atmosphere majestic and warm. The prince’s face is clearly visible, confident and composed, cinematic lighting on his features, 50mm shallow depth.
Video Prompt (Kling)
Camera begins low behind the prince’s boots stepping onto polished stone, then cranes upward to reveal his full figure framed against the glowing palace. Cloak moves naturally in breeze, chariot wheels still turning in background, banners from previous scene flutter in golden light. Subtle push-in as the prince lifts his gaze toward the palace — the soundtrack swells, symbolizing destiny and return.
Generate Images and Videos
Now that we have our inputs (prompts and main character image), we can generate images and videos for each scene.
For the images without the main character, I used Flux Pro like this

In this example, I got the following image:

I then used that image as the first frame to generate a video using Kling 2.5 as follows:

This produced the following video:
For the images with the main character, I used Nano Banana like this:
Notice that I uploaded my main character reference image in the Omni Reference field. I also uploaded the image from the previous prompt showing the caravan since this prompt references it. This prompt generated the following image:

Again, I then used that image as the first frame to generate a video using Kling 2.5 as follows:
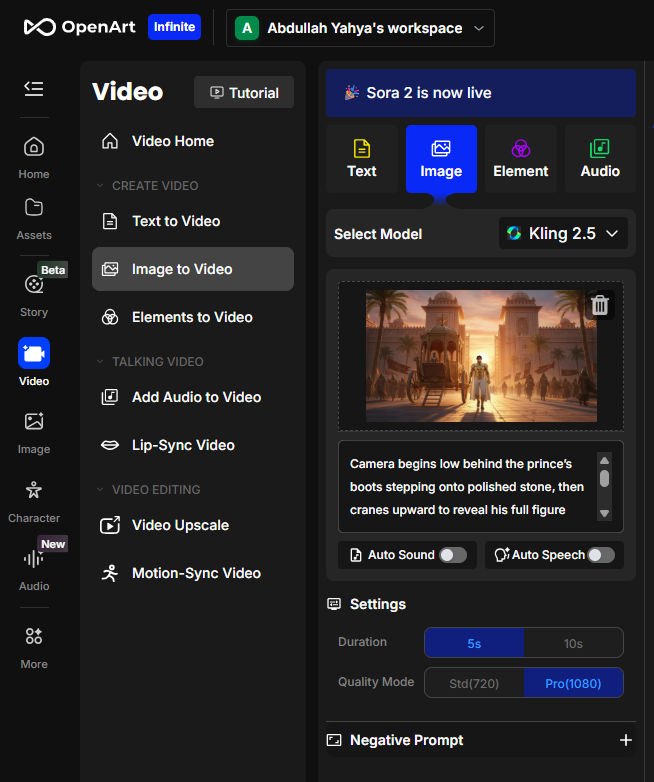
which generated the following video:
Repeat for all prompts
I then just repeated the previous image and video generation step for all the prompts that ChatGPT gave me.
Create final video
Lastly, I added all assets (video clips, music) to a video editing to (I used Capcut), put them on the timeline in my desired sequence, and exported the final video.
Create a poster image
Since I published my video on YouTube, I wanted an attractive thumbnail / poster image. I scrubbed through the video in the timeline in Capcut until I found a frame that I like, and then exported that frame as a still image. I then added the title of the song (“When You Believe”) to it in Photoshop. This is the poster image I ended up with.
