


In this tutorial, I will explain how we can fetch remote paginated JSON data synchronously (in serial) and asynchronously (in parallel).

Data
You can get test data to fetch from RapidAPI, but I’m going to fetch video data from Vimeo using the Vimeo API.
Fetch Method
There are many ways you can fetch remote data. The RapidAPI website provides code snippets for various languages and fetch methods. For example, for Node.js, there’s HTTP, Request, Unirest, Axios, and Fetch.
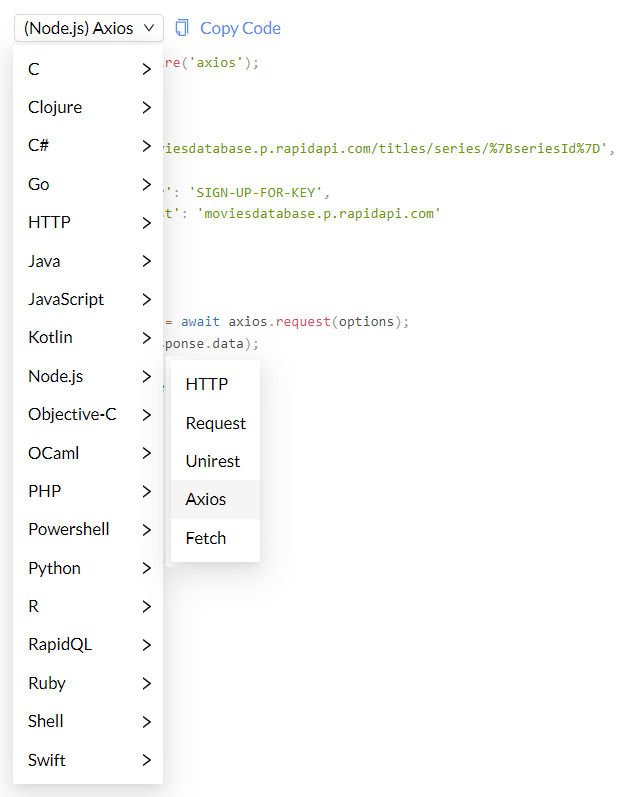
Some services like Vimeo provide libraries and SDKs in a few languages like PHP, Python and Node.js. You can use those as well if you’d like.
I’m actually going to use the Got library [GitHub], which is a very popular library.
CommonJS vs ESM
Many of the latest Node packages are now native ESM instead of CommonJS. Therefore, you can’t require modules like this
const got = require('got');Instead, you must import modules like this
import got from 'got';According to this page, you can convert your project to ESM or use an older version of the got package that uses CommonJS.
If using ESM, you need to put "type": "module" in your package.json.
Authentication
Many services like Vimeo require authentication in order to use their API. This often involves creating an access token and passing it in the header of the API call like this
In cURL:
curl https://api.vimeo.com/tutorial -H "Authorization: bearer {access_token}"As HTTP:
GET /tutorial HTTP/1.1
Host: api.vimeo.com
Authorization: bearer {access_token}Setup
Let’s set up our project. Do the following:
- Create a new folder, e.g. test
- Open the folder in a code editor (I’m using VisualStudio Code)
- Open a terminal (I’m doing it in VS Code)
- Initialize a Node project by running
npm init -y
This will generate a package.json file in the folder.
Since we’re using ESM and will import modules rather than require them, add the following to the package.json file.
"type": "module"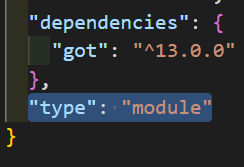
Call the Vimeo API
Let’s start by calling the Vimeo API just once. Create a new file called get-data-one.js and copy the following contents into it. Replace {user_id} with your Vimeo user ID and {access_token} with your Vimeo access token.
import got from 'got';
let page = 1;
let per_page = 3;
let fields = "privacy,link,release_time,tags,name,description,download";
const url = `https://api.vimeo.com/users/{user_id}/videos?page=${page}&per_page=${per_page}&fields=${fields}`;
const options = {
method: 'GET',
headers: {
'Authorization': 'bearer {access_token}'
}
};
let data = await got(url, options).json();
console.log(data);We’re importing the got library. For this to work, we need to install the got package. Run the following command.
npm install gotThis will download the got package and its dependencies into the node_modules folder.
In the code, the Vimeo endpoint we’re calling is /users/{user_id}/videos, which returns all videos that a user has uploaded. According to the API docs, we can
- Specify the page number of the results to show using
page - Specify the number of items to show on each page of results, up to a maximum of 100, using
per_page - Specify which fields to return using
fields
These parameters can be added to the endpoint URL in the query string, which is what we’ve done. However, for this test, we’ll just call one page and return the records (videos). We then call the API using the got library and then dump the results to the console. Let’s run the script and check the output. Run the following command.
node get-data-one.jsAs expected, here’s the output.
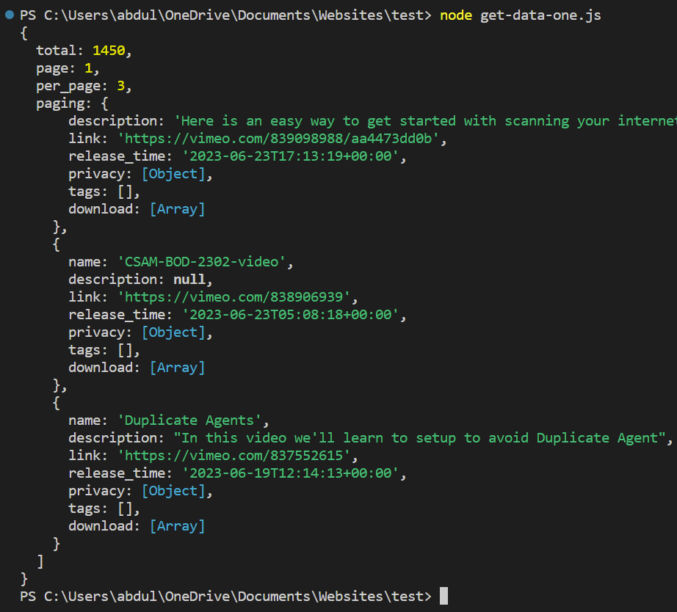
The output starts with pagination info and the total number of available records (videos) followed by the actual data in the form of an array of video objects. In this case, we see 3 objects because we set per_page to 3.
Let’s update our code to write the output to a file. That will make it easier to read when there’s a lot of data. Add the following code snippets
import fs from "fs";var stream = fs.createWriteStream("video-data.json",{flags:'w'});
stream.once('open', function(fd) {
stream.write(JSON.stringify(data)+"\n");
stream.end();
});so the code looks like this:
import fs from "fs";
import got from 'got';
let page = 1;
let per_page = 2;
let fields = "privacy,link,release_time,tags,name,description,download";
const url = `https://api.vimeo.com/users/{user_id}/videos?page=${page}&per_page=${per_page}&fields=${fields}`;
const options = {
method: 'GET',
headers: {
'Authorization': 'bearer {access_token}'
}
};
let data = await got(url, options).json();
console.log(data);
var stream = fs.createWriteStream("video-data.json",{flags:'w'});
stream.once('open', function(fd) {
stream.write(JSON.stringify(data)+"\n");
stream.end();
});
We don’t need to install the fs package because that’s included in Node by default. The stream will write data to a file we’ll call video-data.json and we pass it the “w” flag to overwrite any existing contents of the file.
When we rerun the script, we see the file is created. We can format (prettify) it so it’s easy to read.
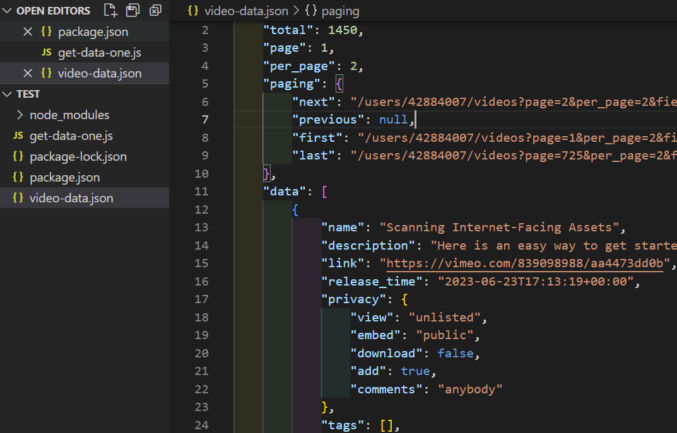
Call the Vimeo API Multiple Times in Serial with Pagination
Now, let’s say we want to fetch more data, but the API limits how many records are returned in a single call. In this case, we need to call the API in a loop passing a different page number. Let’s create a new file called get-data-serial.js with the following code.
import fs from "fs";
import got from 'got';
let data = [];
let per_page = 2;
let fields = "privacy,link,release_time,tags,name,description,download";
const options = {
method: 'GET',
headers: {
'Authorization': 'bearer {access_token}'
}
}
for(let page = 1; page <= 3; page++) {
const url = `https://api.vimeo.com/users/{user_id}/videos?page=${page}&per_page=${per_page}&fields=${fields}`;
let somedata = await got(url, options).json();
data.push(somedata);
console.log(page);
};
console.log(data);
var stream = fs.createWriteStream("video-data.json",{flags:'w'});
stream.once('open', function(fd) {
stream.write(JSON.stringify(data)+"\n");
stream.end();
});
Here, I’m using a simple for loop to loop through 3 pages. I also created a data variable as an empty array. With each loop iteration, I push the page’s returned data to the data array. When all is done, I write the data array to a file, which looks like this.
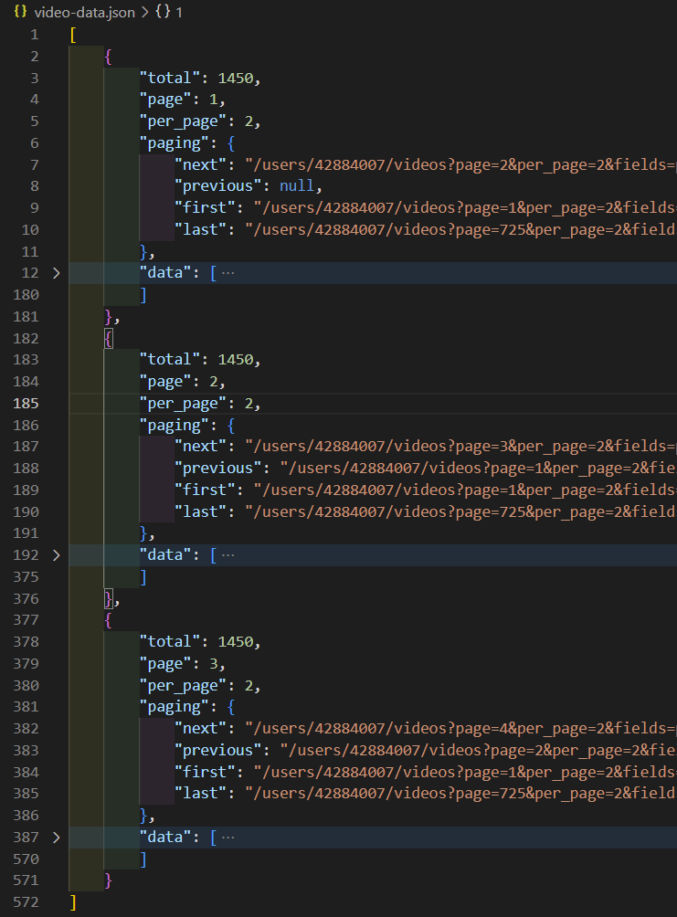
I collapsed the “data” array so we can see that 3 pages of data were returned. We ran this in serial so the order of the output is page 1, page 2, and page 3.
Call the Vimeo API Multiple Times in Parallel with Pagination
Now, let’s do the same thing, but asynchronously (in parallel). Create a new file called get-data-parallel.js with the following code.
import fs from "fs";
import got from 'got';
const options = {
method: 'GET',
headers: {
'Authorization': 'bearer {access_token}'
}
};
let data = [];
let per_page = 2;
let fields = "privacy,link,release_time,tags,name,description,download";
let pages = [1,2,3];
await Promise.all(pages.map(async (page) => {
const url = `https://api.vimeo.com/users/{user_id}/videos?page=${page}&per_page=2&fields=privacy,link,release_time,tags,name,description,download`;
let somedata = await got(url, options).json();
data.push(somedata);
console.log(page);
}));
console.log(data);
var stream = fs.createWriteStream("video-data-parallel.json",{flags:'w'});
stream.once('open', function(fd) {
stream.write(JSON.stringify(data)+"\n");
stream.end();
});
In this case, instead of a for loop, we’re using Promise.all and passing to it an array of page numbers that we loop over using the map function. When we run the script, we get output like the following:
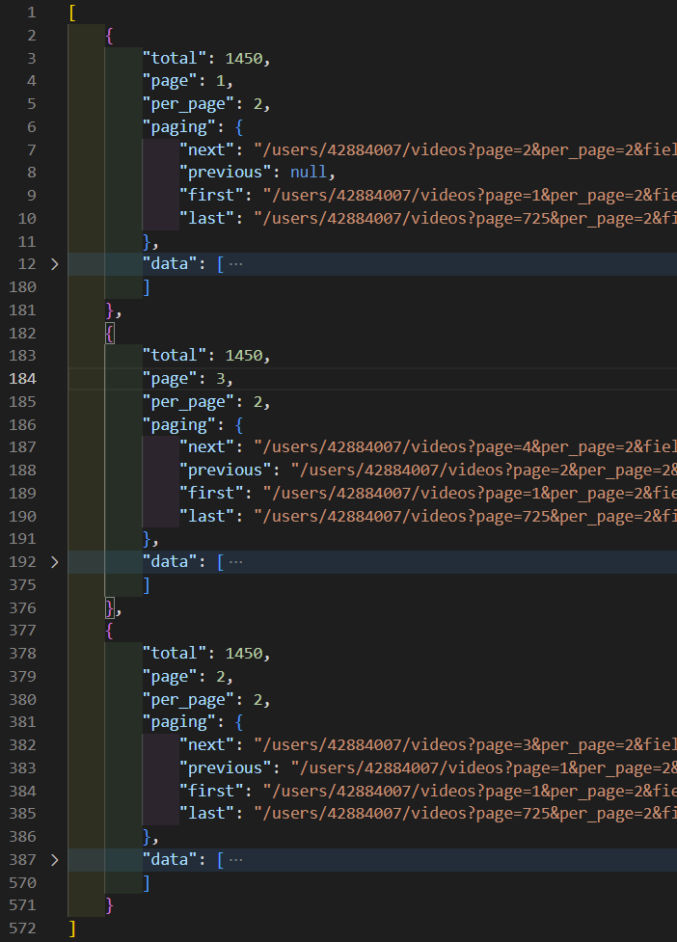
You’ll notice 2 things:
- the script runs faster because the API calls are done simultaneously in parallel (asynchronously) rather than one after the other in serial (synchronously).
- the order of the output is no longer consecutive by page number. In this example, it was page 1, page 3, page 2.
Modifying the JSON Output Structure
As shown in the previous screenshot, the API call returns an object containing pagination info followed by a data array – an array of objects containing video info.
What if we just want the data objects and not the pagination info. We can do that by modifying the structure of the JSON output. We can replace
data.push(somedata);with
data.push(somedata.data);but then the output becomes an array of arrays.
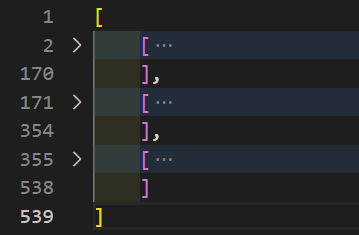
To fix this, let’s flatten the array by adding the following code:
data = data.flat(1);right before we console it out and write to file.
Now, the output file looks like this (each record is collapsed for visibility).
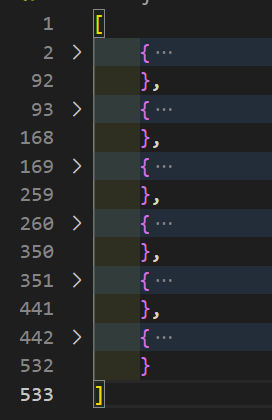
Filtering Out Certain Records
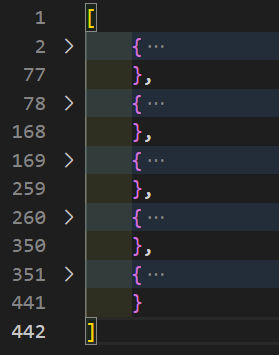
What if we want to filter out certain records, e.g. we want to filter out all videos that are not public, i.e. we only want videos where privacy.view = “anybody”. We can use the filter function to do that, like this:
somedata = somedata.filter(video => video.privacy.view === "anybody" );Now, we only get 5 records instead of 6 because one of them had privacy.view = “unlisted”.
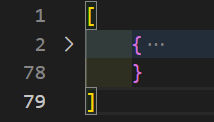
What if we want to exclude videos in the “Educational” category. We can do so like this:
somedata = somedata.filter(function (video, index, arr) {
let isEducational = false;
video.categories.filter(function (category, index, arr) {
if (category.name === "Educational") {
isEducational = true;
}
});
if (isEducational === false) {
return video;
}
});Now, the output is only one record.
Removing Fields From the JSON Output
Each video record can contain a lot of information, including information we don’t need. For example, the privacy object contains 5 keys.
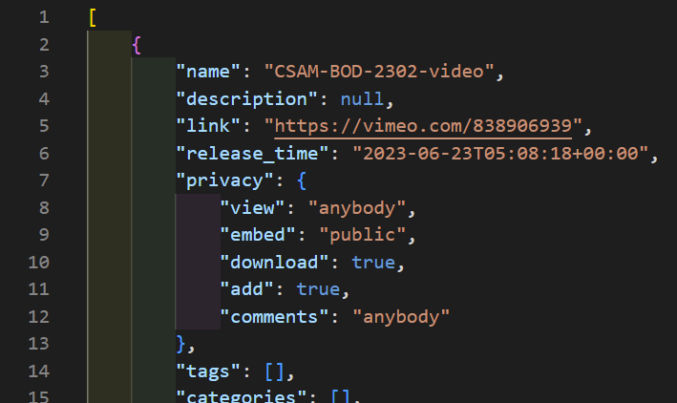
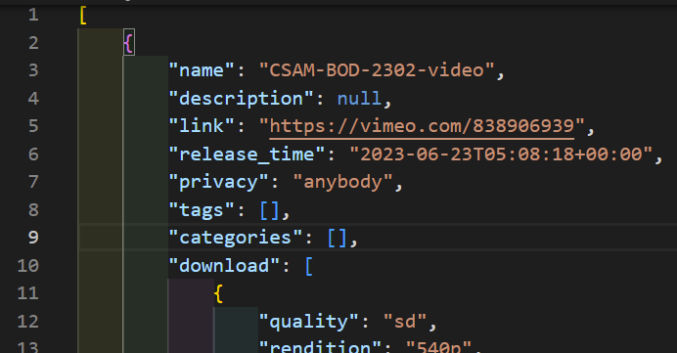
If we want to return just one privacy key, say “view”, then we can do so using the map function as follows:
// simplify privacy object to just privacy.view
somedata = somedata.map(function (video) {
video.privacy = video.privacy.view;
return video;
});
For each video record, the “download” field is an array of objects, one for each available rendition (resolution), e.g.
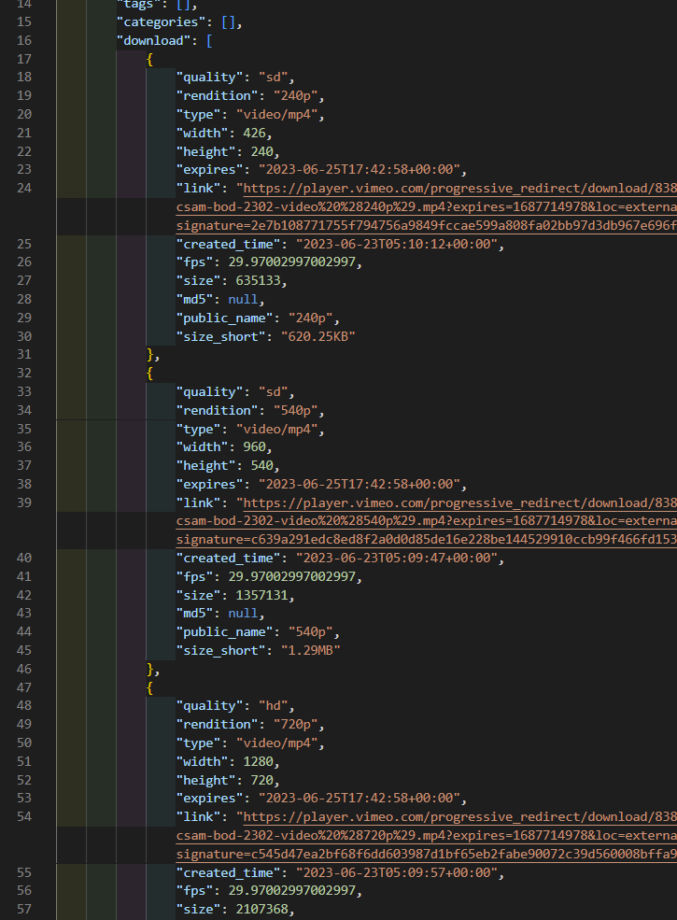
If we only want to, say, return “hd” videos and only the download links, we can use two map functions like this:
// only include videos that are HD and only return HD video download links
somedata = somedata.map(function (video) {
let download = [];
video.download.map(function (size) {
if (size.quality === "hd") {
download.push({
rendition: size.rendition,
link: size.link
})
}
});
if (download.length !== 0) {
video.download = download;
return video;
}
});Now, the downloads array is simplified, like this:
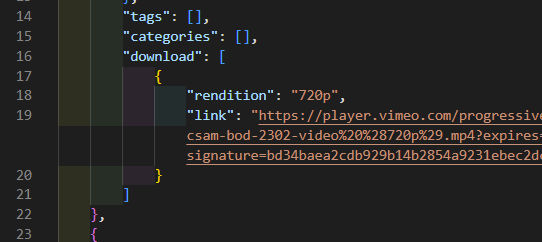
The “categories” field is an array of objects with a lot of data, including objects and arrays of objects.
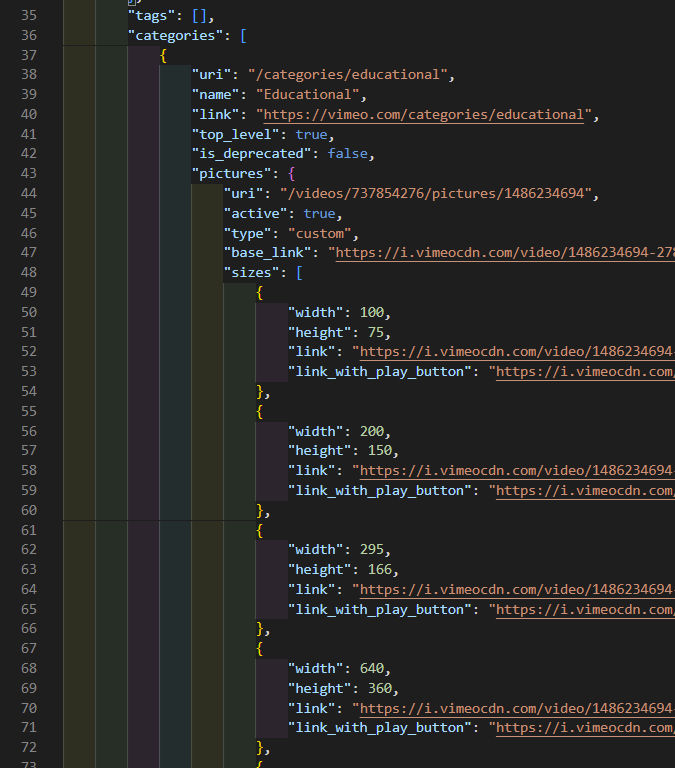
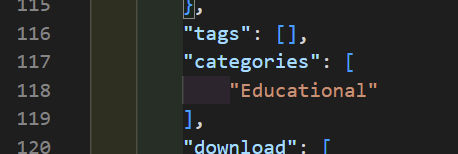
What if we want to simplify that to just a comma-delimited list of category names. We can do that like this:
somedata = somedata.map(function (video) {
let categories = [];
if (video !== undefined) {
video.categories.map(function (category) {
categories.push(category.name);
});
video.categories = categories;
return video;
}
});Now, the “categories” field is much simpler.
Complete Code
For reference, here’s the complete code for get-data-serial.js. The page limit and per_page values can be updated depending on how many results you want.
import fs from "fs";
import got from 'got';
let data = [];
let per_page = 2;
let fields = "privacy,link,release_time,tags,name,description,download,categories";
const options = {
method: 'GET',
headers: {
'Authorization': 'bearer {access_token}'
}
}
for(let page = 1; page <= 3; page++) {
const url = `https://api.vimeo.com/users/{user_id}/videos?page=${page}&per_page=${per_page}&fields=${fields}`;
let somedata = await got(url, options).json();
somedata = somedata.data;
// only include videos that are public
somedata = somedata.filter(video => video.privacy.view === "anybody" );
// only include videos that aren't in the "Educational" category
somedata = somedata.filter(function (video, index, arr) {
let isEducational = false;
video.categories.filter(function (category, index, arr) {
if (category.name === "Educational") {
isEducational = true;
}
});
if (isEducational === false) {
return video;
}
});
// simplify privacy object to just privacy.view
somedata = somedata.map(function (video) {
video.privacy = video.privacy.view;
return video;
});
// only include videos that are HD and only return HD video download links
somedata = somedata.map(function (video) {
let download = [];
video.download.map(function (size) {
if (size.quality === "hd") {
download.push({
rendition: size.rendition,
link: size.link
})
}
});
if (download.length !== 0) {
video.download = download;
return video;
}
});
// simplify categories array of objects to just an array of category names
somedata = somedata.map(function (video) {
let categories = [];
if (video !== undefined) {
video.categories.map(function (category) {
categories.push(category.name);
});
video.categories = categories;
return video;
}
});
data.push(somedata);
console.log(page);
};
data = data.flat(1);
console.log(data);
var stream = fs.createWriteStream("video-data.json",{flags:'w'});
stream.once('open', function(fd) {
stream.write(JSON.stringify(data)+"\n");
stream.end();
});